Cursor Composer 2.5 vs Anthropic & OpenAI
Performance benchmarks and cost comparison — May 2026
Bottom line: Composer 2.5 matches frontier models on several coding benchmarks at roughly 1/10th the per-token cost (Standard tier) or ~1/10th the per-task cost (Fast vs max-effort frontier configs). Opus 4.7 and GPT-5.5 still lead on the Artificial Analysis Coding Agent Index at max reasoning; GPT-5.5 dominates terminal workflows. Composer 2.5 is available only inside Cursor.
Performance Benchmarks
| Benchmark | Composer 2.5 | Claude Opus 4.7 | GPT-5.5 | Notes |
|---|---|---|---|---|
| SWE-Bench Multilingual | 79.8% | 80.5% | 77.8% | Real GitHub issues; Opus leads by ~0.7 pts |
| Terminal-Bench 2.0 | 69.3% | 69.4% | 82.7% | Shell/terminal tasks; GPT-5.5 leads by ~13 pts |
| CursorBench v3.1 | 63.2% | 64.8% max / 61.6% default | 64.3% xhigh / 59.2% default | Cursor-internal; not independently reproducible |
| AA Coding Agent Index | 62 | 66 | 65 | Composite index (Artificial Analysis) |
| SWE-Bench-Pro-Hard-AA | 47% | ~comparable (max) | — | Up from 12% on Composer 2 (+35 pts) |
| Terminal-Bench v2 (AA) | 66% | — | — | Up from 64% on Composer 2 |
| SWE-Atlas-QnA (AA) | 72% | — | — | Up from 69% on Composer 2 |
| Mean time per task (AA) | 6.7 min Fast / 9.3 min Std | ~17.7 min (max) | — | Composer is faster on agent tasks |
| Availability | Cursor IDE/CLI only | API, Claude Code, Cursor | API, Codex, Cursor | Composer has no public API |
Sources: Cursor launch benchmarks (May 2026), Artificial Analysis. Cursor has cautioned that standard SWE-Bench scores can overstate ability when models retrieve known fixes from repo history.
Cost — Per-Token API Pricing per 1M tokens
| Model / Tier | Input | Output | vs Composer 2.5 Standard | vs Composer 2.5 Fast |
|---|---|---|---|---|
| Composer 2.5 Standard | $0.50 | $2.50 | — | 6× cheaper |
| Composer 2.5 Fast default | $3.00 | $15.00 | 6× more expensive | — |
| Claude Opus 4.7 | $5.00 | $25.00 | 10× input, 10× output | ~1.7× input/output |
| GPT-5.5 | $5.00 | $30.00 | 10× input, 12× output | ~1.7× input, 2× output |
Cost — Estimated Per Agent Task Artificial Analysis
| Model / Configuration | Cost per Task | Index Score | Cost Efficiency |
|---|---|---|---|
| Composer 2.5 Standard | $0.07 | 62 | Best cost/score ratio |
| Composer 2.5 Fast | $0.44 | 62 | ~30% faster than Standard |
| Claude Opus 4.7 max (Claude Code) | $4.10 | 66 | ~10× (Fast) to ~60× (Std) more |
| GPT-5.5 xhigh (Codex) | $4.82 | 65 | ~11× (Fast) to ~69× (Std) more |
Cost Multiples — Quick Reference
| Comparison | Input Tokens | Output Tokens | Per-Task (AA est.) |
|---|---|---|---|
| Composer 2.5 Standard vs Opus 4.7 | 10× cheaper | 10× cheaper | ~60× cheaper |
| Composer 2.5 Standard vs GPT-5.5 | 10× cheaper | 12× cheaper | ~69× cheaper |
| Composer 2.5 Fast vs Opus 4.7 | ~1.7× cheaper | ~1.7× cheaper | ~10× cheaper |
| Composer 2.5 Fast vs GPT-5.5 | ~1.7× cheaper | 2× cheaper | ~11× cheaper |
Leadership Presentation
Evolving Field Engineering as Cursor goes upmarket
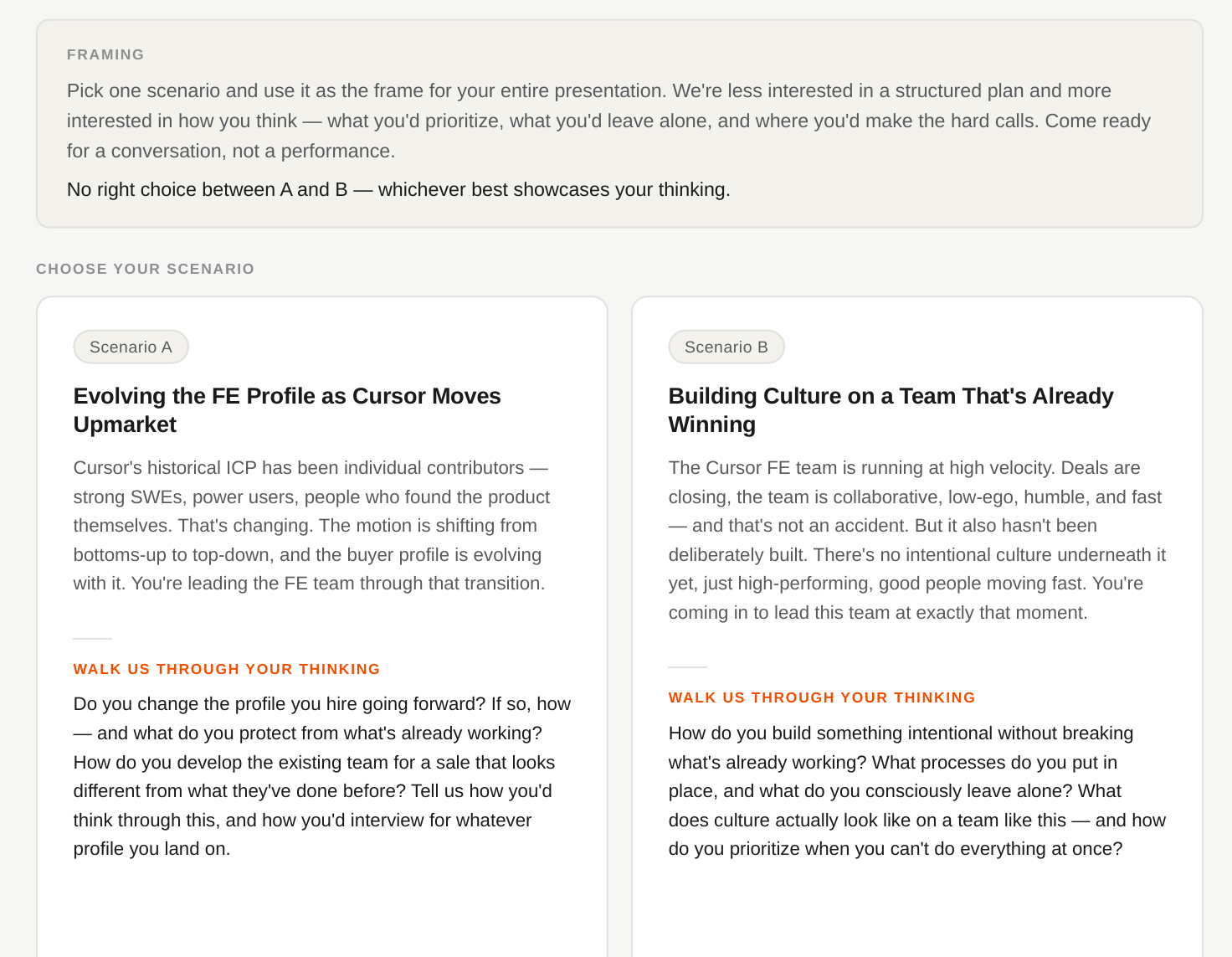
The sale is changing from bottoms-up to top-down
- IC power users who found Cursor themselves
- Sell depth to engineers who already want it
- Remove technical friction — product-led pull
- CTO / VP buyers and multi-stakeholder evals
- Security, procurement, ROI, change management
- Drive org-wide adoption against inertia
Same product value. Still fundamentally technical. The failure mode is over-rotating to polish and losing the credibility that wins the eval.

The evolved FE profile — on top of the technical bar

Executive presence
Carry a CTO / VP room, not just a working session with engineers. Solve: Stand and Deliver training

Structured enterprise evals
Run POCs with explicit success criteria and multi-threaded stakeholders. Solve: Path to Production

Business-value & ROI fluency
Translate developer-productivity gains & token efficiency into a CFO-legible case. Solve: Path to Production

Procurement & security navigation
Clear the gatekeepers of a top-down enterprise deal. Solve: Path to Production

Change-management instinct
Drive org-wide adoption against inertia, not just delight one power user. Solve: 3 circles of leadership, on every call
The non-negotiables — restraint is the senior move

Technical depth & credibility
What the product is actually sold on. Non-negotiable.

Low-ego, fast, builder culture
And genuine daily product usage. This can't be faked.

The bottoms-up engine
Champions create pull. Land-and-expand drives ARR.

Speed
Don't let enterprise process slow the team to a crawl.


